

Java를 활용하다 보면 데이터를 처리할 때 우선순위를 지켜야 하는 상황이 있습니다. 이때 사용할 수 있는 자료구조가우선순위 큐(Priority Queue)입니다.
우선순위 큐를 사용하면 우선순위가 높은 데이터를 먼저 처리할 수 있어서 시스템의 성능을 개선하고 효율적인 데이터 관리를 할 수 있습니다.
이 글에서는 Java의 우선순위 큐(Priority Queue)에 대해 알아보고, 사용 방법과 예제를 통해 그 장단점을 살펴보겠습니다.
선형구조_ 우선순위 큐(Priority Queue)
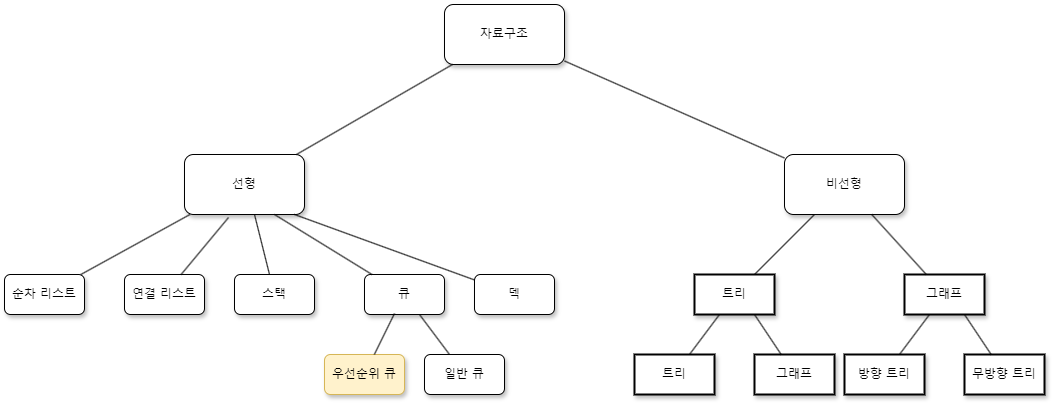
우선순위 큐는 선형구조 중 하나입니다.
선형 자료구조는 데이터가 순차적으로 배치되고 접근되는 구조를 말합니다.

일반적 큐는 선형적인 형태를 띠고 있지만 우선순위 큐는 일반적으로 힙(heap)이라는 트리 구조를 기반으로 구현됩니다.
따라서 우선순위 큐는 트리 구조로 보는 것이 합리적입니다.
우선순위 큐와 힙(heap)의 관계
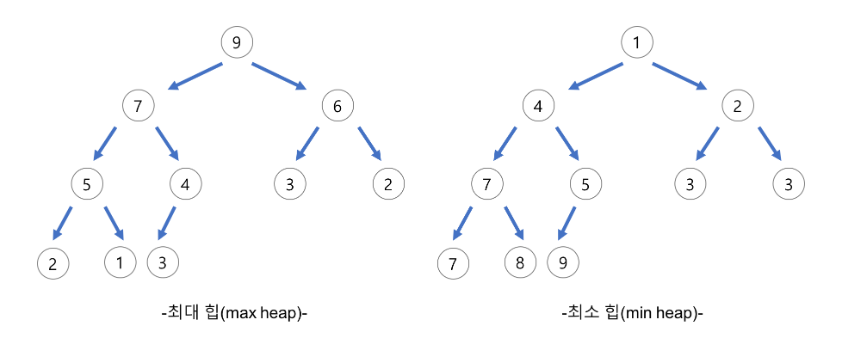
앞서 말했듯이 우선순위 큐는 일반적으로 힙(heap)이라는 트리 구조를 기반으로 구현됩니다.
힙은 부모 노드의 우선순위가 항상 자식 노드의 우선순위보다 높은 완전 이진트리(Complete Binary Tree)를 말합니다.
따라서 우선순위 큐의 대부분의 구현은 이 트리 구조를 이용하여 데이터를 저장하고 우선순위를 관리합니다.
- 힙(Heap) 구조
- 힙은 최대 힙(Max Heap)과 최소 힙(Min Heap)으로 나뉩니다.
- 최대 힙은 부모 노드가 자식 노드보다 항상 크거나 같은 값을 갖는 구조이며, 최소 힙은 그 반대입니다.
- 우선순위 큐는 이러한 힙 구조를 이용하여 우선순위가 높은 데이터를 빠르게 접근하고 처리할 수 있습니다.
- 트리 구조
- 힙은 일종의 트리 구조이며, 일반적으로 배열을 이용하여 구현됩니다.
- 배열을 사용하면 부모 노드의 인덱스와 자식 노드의 인덱스 간의 관계를 쉽게 계산할 수 있습니다.
힙(Heap)의 자세한 내용은 따로 정리를 한 포스팅에서 보실 수 있습니다.
우선순위 큐의 동작방식
최소 heap 삽입과정

- 6의 숫자가 들어오게 되면 우선 마지막에 넣어줍니다.
- 그다음, 부모 노드의 숫자와 비교해서 부모보다 자식 노드의 숫자가 더 작으면 swap을 해줍니다.
- 부모 노드와 비교해서 부모 노드의 숫자가 더 작으면 swap은 이루어지지 않습니다.
최대 heap 삽입 과정

- 15의 숫자가 들어오게 되면 우선 마지막 오른쪽 하단에 넣어줍니다.
- 15는 부모 노드인 7보다 크기 때문에, 위치를 조정하여 최대 힙의 성질을 만족시킵니다.
- 15와 7의 위치를 교환하여 최대 힙의 구조를 유지합니다.
- 그리고 15는 부모 노드인 10보다 크기 때문에, 위치를 조정하여 최대 힙의 성질을 만족시켜 줍니다.
- 15와 10의 위치를 교환하여 최대 힙의 구조를 유지합니다.
- 그리고 15는 부모 노드인 20보다 작기 때문에 더 이상 swap은 이루어지지 않습니다.
힙의 삭제 과정

- 최소 힙에서는 루트 노드(가장 작은 값)를 삭제합니다.
- 삭제된 위치에 힙의 마지막 노드를 옮깁니다.
- 옮겨진 노드를 아래쪽 자식 노드와 비교하여 작은 값과 위치를 교환합니다.
- 교환된 노드 위치에서 다시 힙의 성질을 만족하도록 재구성합니다.
최대 힙도 루트노드가 가장 큰 값인 것과 힙의 성질을 유지하는 부분을 제외하고는 동일하게 동작합니다.
우선순위 큐는 일반적인 큐(Queue)와는 동작 방식이 다릅니다.
큐(Queue)에서는 FIFO(First-In-First-Out) 방식으로 데이터가 처리됩니다.
반면에 우선순위 큐(Priority Queue)는 데이터의 우선순위에 따라 처리되며, 일반적으로 힙(Heap)이라는 자료구조를 사용하여 구현됩니다.
- 삽입 (Enqueue):
- 우선순위 큐에 새로운 데이터를 삽입할 때, 데이터는 해당 데이터의 우선순위에 맞는 위치에 삽입됩니다.
- 일반적으로는 힙(Heap)이라는 완전 이진트리를 사용하여 구현됩니다. 최소 힙(Min Heap)이나 최대 힙(Max Heap)을 이용하여 데이터를 삽입합니다.
- 삽입 시간 복잡도는 O(log n)입니다. 이는 힙의 높이에 따라 결정됩니다.
- 추출 (Dequeue):
- 우선순위가 가장 높은 데이터(최소 힙의 경우 가장 작은 값, 최대 힙의 경우 가장 큰 값)를 제거하여 반환합니다.
- 힙의 루트 노드에 위치한 데이터가 추출됩니다.
- 추출 후에는 힙의 특성을 유지하기 위해 다시 힙을 재구성해야 할 수 있습니다. 이 과정에서 다른 데이터들이 올바른 위치에 존재하도록 조정됩니다.
- 추출 시간 복잡도도 O(log n)입니다.
우선순위 큐(Priority Queue)의 선언방식
우선순위 큐(Priority Queue)는 자바에서 java.util.PriorityQueue 클래스를 사용하여 선언합니다.
우선순위 큐는 데이터를 우선순위 순서에 따라 관리하는 자료구조로, 일반적으로 작은 값이 우선순위가 높은 형태입니다 (최소 힙)
기본 생성자를 사용한 선언
PriorityQueue<Integer> pq = new PriorityQueue<>();
위의 예시에서는 Integer 타입을 저장하는 기본적인 우선순위 큐를 선언합니다.
이 경우 기본적으로 오름차순으로 정렬되는 최소 힙이 생성됩니다.
Comparator를 사용한 선언
PriorityQueue<Integer> pq = new PriorityQueue<>(Collections.reverseOrder());
Collections.reverseOrder()를 사용하면 역순으로 정렬되는 우선순위 큐를 생성할 수 있습니다.
즉, 내림차순으로 정렬되는 최대 힙이 생성됩니다.
우선순위 큐(Priority Queue)의 특징
1. 우선순위에 따른 정렬
- 작은 값이 높은 우선순위
- 일반적으로 우선순위 큐는 작은 값이 더 높은 우선순위를 가지는 최소 힙(Min Heap)으로 구현됩니다.
- 따라서 가장 작은 값이 가장 높은 우선순위를 가지고, 제거할 때는 우선순위가 가장 높은 요소가 먼저 제거됩니다.
- Comparator를 이용한 사용자 정의 정렬
- Java에서는 PriorityQueue의 생성자를 통해 Comparator를 지정하여 원하는 우선순위 정책에 따라 정렬할 수 있습니다.
- 예를 들어, Collections.reverseOrder()를 사용하면 큰 값이 우선순위가 높은 최대 힙(Max Heap)을 구현할 수 있습니다.
2. 내부 구현
- 이진 힙(Binary Heap) 기반
- 대부분의 우선순위 큐 구현은 이진 힙을 기반으로 합니다.
- 이진 힙은 완전 이진트리로 구성되며, 부모 노드는 항상 자식 노드보다 우선순위가 높은 구조입니다.
- 이로 인해 데이터의 삽입과 삭제 연산이 O(log n)의 시간 복잡도를 가집니다.
3. 동일한 우선순위 처리
- 동일한 우선순위의 처리
- 우선순위 큐에서는 동일한 우선순위를 가진 요소를 추가할 수 있습니다.
- 이 경우 FIFO(First-In-First-Out) 순서에 따라 처리됩니다.
4. 데이터의 중복
- 데이터의 중복
- 기본적으로 우선순위 큐는 데이터의
중복을 허용하지 않습니다. - 동일한 요소를 여러 번 추가하더라도 한 번만 저장됩니다.
- 기본적으로 우선순위 큐는 데이터의
큐(Queue)의 메서드
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// 우선순위 큐 생성
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 데이터 추가
pq.offer(10);
pq.offer(7);
pq.offer(15);
pq.offer(3);
pq.offer(20);
System.out.println("우선순위 큐의 모든 요소:");
while (!pq.isEmpty()) {
System.out.println(pq.poll());
}
}
}우선순위 큐의 모든 요소:
3
7
10
15
20
위 코드는 기본적으로 우선순위 큐는 작은 값이 더 높은 우선순위를 가지는 큐이기 때문에 실행결과를 보면 큐에 삽입한 순서와 다르게 우선순위 큐는 작은 값이 먼저 출력되는 것을 볼 수 있습니다.
중복된 우선순위를 가지는 경우
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// 우선순위 큐 생성
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 데이터 추가
pq.offer(10);
pq.offer(5);
pq.offer(10); // 중복된 우선순위 요소 추가
pq.offer(20);
pq.offer(15);
pq.offer(5); // 또 다른 중복된 우선순위 요소 추가
pq.offer(3);
System.out.println("우선순위 큐의 모든 요소:");
while (!pq.isEmpty()) {
System.out.println(pq.poll());
}
}
}우선순위 큐의 모든 요소:
3
5
5
10
10
15
20
'자료구조' 카테고리의 다른 글
| [JAVA] HashSet 클래스 사용법 (중복 없는 데이터 집합) (0) | 2024.06.29 |
|---|---|
| [JAVA] HashMap_entrySet() : 데이터 접근과 반복을 간편하게 하는 방법(2/2) (0) | 2024.06.28 |
| [자료구조 JAVA] 선형 구조 큐(Queue) 클래스 알아보기 ✔ (0) | 2024.06.15 |
| [자료구조 JAVA] LinkedHashSet 알아보기 (1/2) (1) | 2024.06.15 |
| [자료구조 JAVA] 스택 Stack 컬렉션 알아보기 (1/2) (0) | 2024.06.13 |