
개요
문자열 검색 알고리즘은 두 문자열을 비교하여 특정 패턴이 주어진 텍스트에서 처음 등장하는 위치를 찾거나, 특정 조건을 만족하는 서브스트링을 효율적으로 찾는 데 사용됩니다.
일반적인 문자열 검색은 O(N * M) 복잡도를 가지며, 이는 텍스트의 길이 N과 패턴의 길이 M에 비례하여 비교를 수행하기 때문에 긴 문자열을 다룰 때 비효율적입니다.
이를 개선하기 위해 KMP(Knuth-Morris-Pratt) 알고리즘이 고안되었습니다. 이번 포스팅에서는 KMP(Knuth-Morris-Pratt) 알고리즘에 대해서 정리하고자 합니다.
KMP(Knuth-Morris-Pratt) 알고리즘이란❓
KMP 알고리즘의 핵심은 pi 배열을 사용해, 패턴 내에서 중복된 접두사와 접미사 정보를 미리 계산하고 이를 활용하여 텍스트 탐색 중 발생하는 불필요한 비교를 제거하는 것입니다.
KMP는 패턴의 반복 구조를 분석하여 미리 pi 배열이라는 정보를 생성하고, 이를 통해 텍스트 내에서 불필요한 중복 비교를 최소화합니다. 따라서 KMP 알고리즘은 문자열 길이에 비례하는 O(N + M) 시간 복잡도를 가지며, 텍스트 검색 속도가 크게 향상됩니다.
1. 부분 일치 테이블(pi 배열) 생성
pi 배열은 각 인덱스까지의 부분 문자열에서 접두사와 접미사가 일치하는 최대 길이를 저장합니다.
이 정보를 통해 패턴의 일치가 실패했을 때 비교할 위치를 재설정합니다. 예를 들어, "ABCDABD"라는 패턴의 경우 pi 배열은 [0, 0, 0, 0, 1, 2, 0]이 됩니다.
2. 텍스트와 패턴 비교
패턴을 텍스트와 비교할 때 일치하는 문자가 나오면 텍스트와 패턴의 포인터를 모두 한 칸씩 이동합니다. 만약 일치가 실패하면 pi 배열을 통해 미리 계산된 위치로 이동하여 비교를 이어갑니다.
예시를 통해 알아보자❗️
일반 문자열 비교

1번 째 String 비교
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String B 비교 ➡️ 매칭 ❌
2번 째 String 비교
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String B 비교 ➡️ 매칭 ❌
3번 째 String 비교
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String A 비교 ➡️ 매칭 : 포인터 이동
- 1번째 String A와 2번째 String B 비교 ➡️ 매칭
위와 같이 O(N*M)의 시간복잡도가 형성되는 것을 알 수 있습니다. 이는 효율적이지 않습니다.
1번째 String 비교를 한 다음에 매칭이 되지 않았기 때문에 다음 인덱스로 이동하여 비교를 하게 됩니다. 이 때 왼쪽의 문자들을 보면 A가 반복되는 것을 알 수 있습니다.

따라서 "1번 째 String비교"에서 이미 비교한 부분 문자열이 같다는 정보가 패턴에서 뽑아낼 수 있다는 것입니다. 즉, X의 매칭을 없앨 수 있다는 것부터 KMP알고리즘이 시작됩니다.
KMP 예제 1번
그러면 부분 문자열에서 반복되는 패턴을 뽑아내야합니다. 패턴을 뽑아내기 위해서는 정보를 기입해야 합니다.
반복되는 문자열이 없으면 0 있으면 1이 됩니다. 여기서 1의 의미는 이 부분 문자열의 반복이 해당 인덱스 전 까지 같다는 것을 의미합니다. 이러한 규칙을 계속해서 쌓아가다면 반복되는 패턴을 뽑을 수 있습니다.

위 그림에서 알 수 있듯이 문자열 "AAAB"가 있다면 패턴인 pi 배열은 [0, 1, 2, 0]입니다.
인덱스 0에서는 반복이 없으므로 0, 인덱스 1과 2에서는 접두사("A", "AA")와 접미사("A", "AA")가 일치하므로 각각 1과 2가 됩니다. 인덱스 3에서는 이전 문자와 다르므로 0이 됩니다.
이해를 돕기 위해 또 다른 예제를 가져왔습니다.

패턴 "ABCABD"의 pi 배열은 [0, 0, 0, 1, 2, 0]이 됩니다.
- 처음에는 ➡️ 0
- B는 그 전에 반복되는 글자가 없기 때문에 ➡️ 0
- C도 그 전에 반복되는 글자가 없기 때문에 ➡️ 0
- A는 1번째 인덱스(B) 전에 반복되기 때문에 ➡️ 1
- B는 2번째 인덱스(C) 전에 반복되기 때문에 ➡️ 1
- D는 그 전에 반복되는 글자가 없기 때문에 ➡️ 0
그러면 이제 패턴을 알았기 때문에 String Matching을 할 수 있습니다.

마찬가지로 "AAAAABB"와 "AAAB"를 예시로 설명해 보겠습니다.
B에서 Miss Match가 일어났습니다. 이 때 패턴에서 Miss Match가 일어난 인덱스의 전 정보 "3"을 가져옵니다.
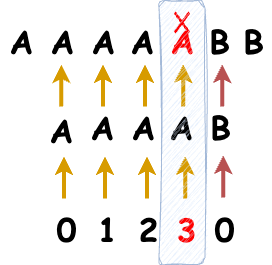
그리고 인덱스 3인 "A"와 Miss Match 가 일어난 문자 "A"를 맞춰 주고, 다시 탐색을 시작합니다. 그리고 패턴의 정보를 알고있기 때문에 굳이 다시 반복하지 않고 패턴의 3번째 인덱스부터 매칭을 검사해주게 됩니다.
그러면 3번째 인덱스부터 비교를 하고, 1번째 문자열의 A와 2번째 문자열의 A가 같고, 그 다음 문자인 B와 B가 같기 때문에 Matching이 되는 부분 문자열을 찾게됩니다.
KMP 예제 2번
그러면 또 다른 예제에서 확인해보겠습니다. 1번째 문자열이 "d a b c a b k a b c a b d" 이고, 2번째 문자열이 "a b c a b d" 일 경우를 확인해보겠습니다.

첫 번째 비교부터 Miss Match가 일어나기 때문에 다음 인덱스와 비교를 해줍니다. 계속 매칭되다가 마지막에 k ↔️ d일 때 Miss Match가 일어납니다.
그러면 Miss Match가 일어난 문자 전의 패턴 정보(2)를 읽고, 해당 문자(c)와 Miss Match가 일어난 1번째 문자열의 문자(k)와 비교를 해줍니다.
비교를 해주기 위하여 2번째 문자열을 이동시키면 다음과 같이 나오게 됩니다.

이동한 뒤 다시 비교을하면 k ↔️ c 일때 Miss Match가 발생했습니다. 그러면 마찬가지로 Miss Match가 일어난 문자 전의 패턴 정보(0)를 읽고, 해당 문자(a)와 Miss Match가 일어난 1번째 문자열의 문자(k)와 비교를 해줍니다.
k ↔️ a 도 Miss Match가 일어나기 때문에 전체적으로 한칸을 이동해줍니다.

한칸을 이동하고 문자를 서로 비교하면 1번째 문자열의 "abcabd"와 2번째 문자열의 "abcabd"가 같기 때문에 SubString을 찾아냅니다.
이와 같이 비교가 될 문자열의 반복 패턴정보를 기억하고있다가 이 패턴 정보를 이용해서 불일치가 발생해도 패턴의 이전 부분을 다시 탐색하지 않으므로 효율적입니다.
'Algorithm' 카테고리의 다른 글
| [Algorithm] 백트래킹(Backtracking) 알고리즘 알아보기 (0) | 2024.11.27 |
|---|---|
| [Algorithm] 효율적인 소수 판별: 기본 방법부터 에라토스테네스의 체까지 (0) | 2024.11.26 |
| [Algorithm] 이진 탐색 알고리즘 : 데이터 정렬과 검색 최적화 (Binary Search, Java) (0) | 2024.07.09 |
| [Algorithm] 효율적인 그래프 탐색: 자바로 구현한 DFS 알아보기 (1/2) (0) | 2024.07.07 |
| [Algorithm] 그리디 알고리즘(탐욕법, greedy, Java) 알아보기 (0) | 2024.05.30 |